Evolutionary development depends on continuous iterations with the customer, being a final customer or not, like an intern QA engineer. If you create unit tests in your evolutionary development process, you can also work with evolutionary unit tests. An evolutionary unit test can be used on code hardening tasks, because you must make your test fail using unexpected environment behaviour, for example passing null references to your unit tests, avoiding the well known “Null References: The Billion Dollar Mistake”, once the code is refactored to support null references.
You can start checking the “2011 CWE/SANS Top 25 Most Dangerous Software Errors” using your unit tests. Regarding the best programming practices, and even using style checkers and static analysis tools, you will be generating better code. So, the cycle is simple while you are testing your application:
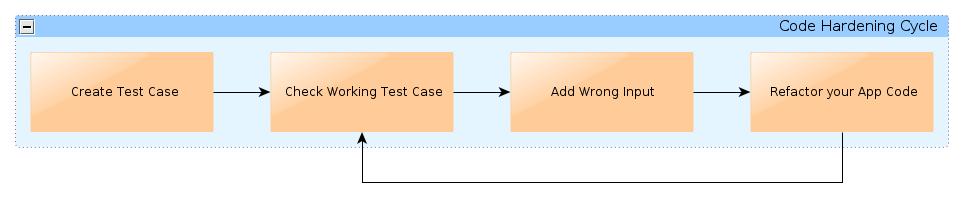
- Create a Test Case.
- Check that the Test Case runs correctly.
- Choose a well known error, for example null references.
- Change the Test Case and add the wrong input to your code.
- Refactor the application hardening its input.
- Check that the Test Case runs correctly with wrong input.
- Document your progress with source code comments or annotations.
- Choose another error and make the Test Case fail again.
There is also some interesting papers and documents with some techniques that you can integrate in your development process, so you can create more stable code, mostly applied to Object-Oriented software and strongly-typed languages, which are talking about using manually created evolutionary tests to using genetic programming for those tasks. I hope that we can see the results of that research using genetic programming to automate the test handling process. The advantage of strongly-typed languages is the fact that most of them require to be statically-typed, which means that your code must follow well implemented type declarations and variable declaration using the proper types. So, the type system on those languages can be used to ensure that implementations are correctly done.
Initially, the test cluster for the given class under test is defined using static analysis. The concerned classes are then instrumented; thereby, the test goals — in our case all branches of the methods of the class under test — are collected. We follow the goal oriented approach and carry out a search for a test program for each individual test goal.
Static analysis again plays an interesting role on this approach, where is easier to handle static analysis on strongly-typed languages, rather than using static analysis on dynamically-typed languages.
When comparing evolutionary-based approaches over random testing [21] several prominent advantages arise, which include: less need for human analysis, as the evolutionary algorithm pre-analyses the software in accordance to the fitness function; the ability to automatically test combinations of suspicious parameters; and the possibility of finding combinations of inputs that lead to a more severe fault behaviour. Drawbacks include the difficulty of detecting solitary errors (“needles in a haystack”) with greater efficiency than random testing, and the impossibility of guaranteeing code coverage in black-box testing.
But if we have a lack of that kind of tools in our environment, so we must do that kind of analysis manually, and manually make our test to be tested against suspicious environment conditions, so we can use manual evolutionary unit testing. I hope that you will enjoy hardening your code ;)
